
GLM-4.6 vs Sonnet 4.5 — Open-Source Diff-Edit Convergence | Cline Report
This week marked an inflection point for AI coding. Anthropic’s Claude Sonnet 4.5 landed on Monday; zAI’s GLM-4.6 followed on Tuesday. Both models were well-received, but the deeper story lives in Cline’s real-world telemetry: on the hardest coding task mode we track—diff edits—the performance gap between premium and open models has narrowed to basis points, not percentage points.
An open source convergence
The Artificial Analysis Coding Index has been tracking this trend for months. Open source models are catching closed source in intelligence, but even faster in coding ability. This isn't speculation; it's measurable in benchmarks, real-world usage, and now, in our own data from millions of Cline operations.
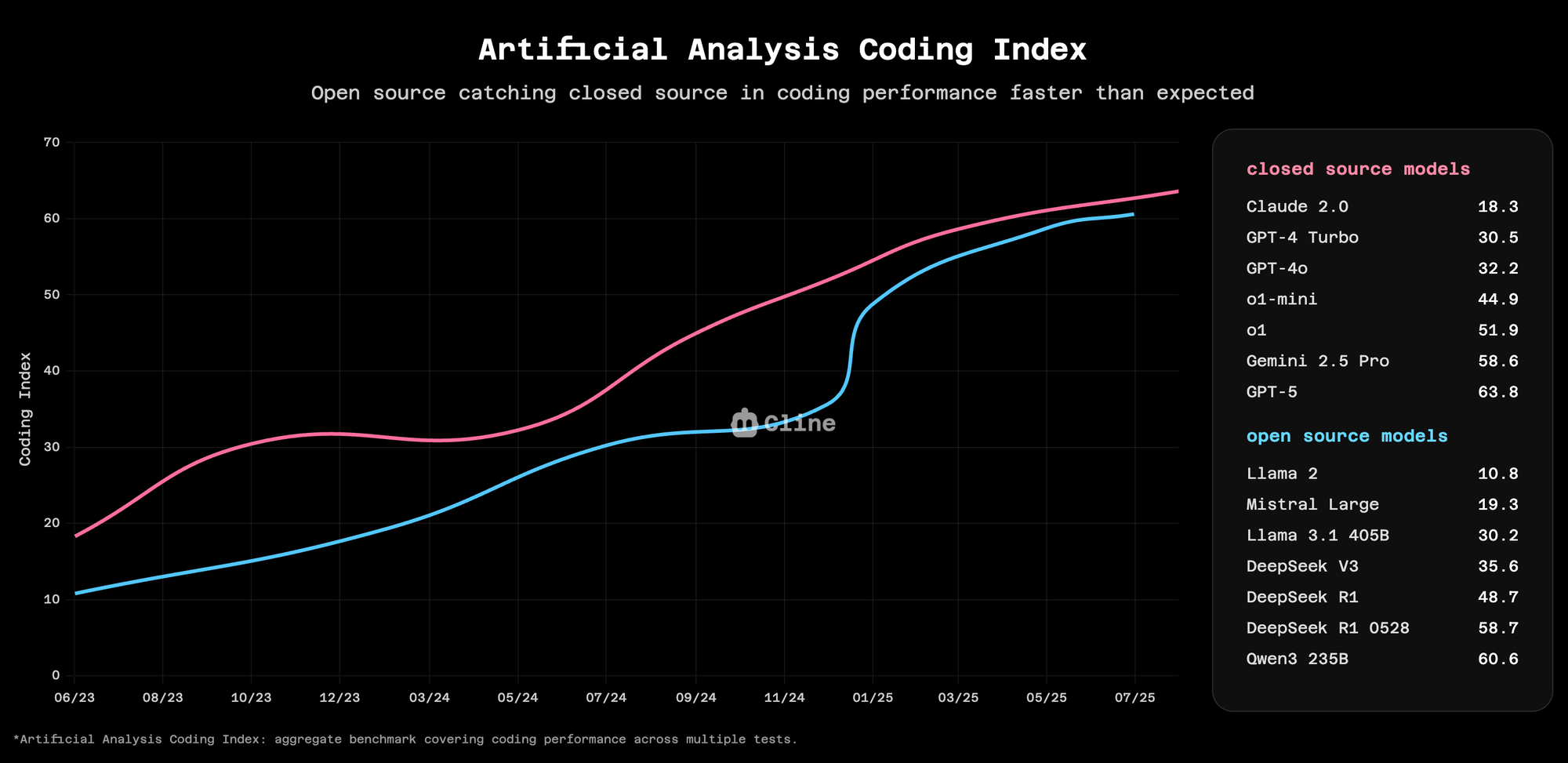
Why Cline's data matters
Diff edits are the hardest test for AI coding models. They require understanding context, maintaining consistency, and making precise surgical changes to existing code. Unlike generating new code from scratch, diff edits test whether a model truly understands what it's modifying.
We analyzed millions of diff edit operations from Cline users over the past four months. The results tell a clear story about this week's releases.
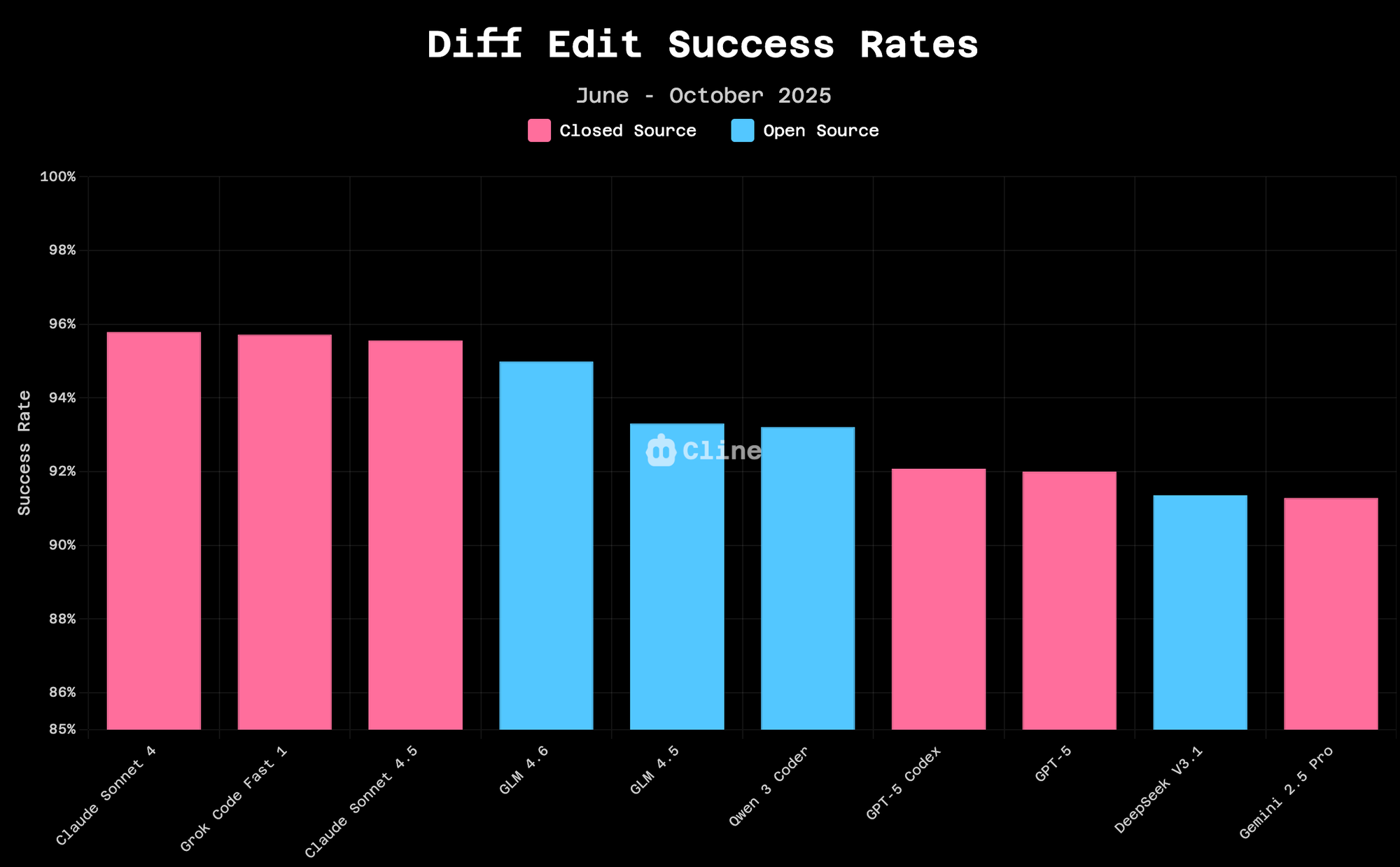
The performance clustering is striking. Claude 4 Sonnet achieves 95.8% success rate on diff edits. Claude 4.5 Sonnet edges slightly higher at 96.2%. GLM-4.6 comes in at 94.9% success rate. These differences are measurable but marginal; we're talking about a gap of basis points, not percentage points.
For context, just three months ago, the gap between premium and open models on these tasks was 5-10 percentage points. The convergence is accelerating.
Community pulse inside Cline
Developers on Cline’s Discord described Sonnet 4.5 as “needing half the corrections,” with tighter instruction following and cleaner first drafts. GLM-4.6 drew excitement for getting “close to Sonnet at a fraction of the cost,” often benchmarking alongside Sonnet 4.5 in real projects. The enthusiasm isn’t just about raw performance—it’s about access.
The economics can't be ignored
The cost differential between these models is substantial:
- Claude Sonnet 4.5: $3 per million input tokens, $15 per million output tokens
- GLM-4.6: $0.50 per million input tokens, $1.75 per million output tokens
- Qwen3 Coder: $0.22 per million input tokens, $0.95 per million output tokens
zAI's GLM Coding Plan takes this further, offering GLM-4.6 access for just $6/month with 120 prompts per 5-hour cycle. For many developers, this transforms AI coding from a luxury to a utility.
What this convergence means
The trend lines are clear. Open source models continue to improve at a faster rate than closed source models. While this trend doesn't imply open source will certainly supersede the closed source frontier, each release narrows the gap further. GLM-4.6 achieving 95% success rate on diff edits would have been unthinkable for an open model six months ago.
The convergence extends beyond cloud models. This week, AMD demonstrated that models like Qwen3 Coder can run effectively on consumer hardware with just 32GB RAM. The gap isn't just closing in the cloud; it's closing on your laptop.
As models converge in capability, differentiation will come from ecosystem, tooling, and specialized features. The fundamentals of good code generation are becoming commoditized. What matters next is how these models integrate into developer workflows.
Ready to try these models? Download Cline and experiment with both GLM-4.6 and Sonnet 4.5. Join the conversation on Reddit and Discord to share your experiences.


