
Which local models actually work with Cline? AMD tested them all
AMD published their comprehensive guide to local "vibe coding" with Cline, LM Studio, and VS Code. After testing over 20 models, they discovered that only a handful actually work reliably for coding tasks. Most smaller models produce broken outputs or fail entirely.
While AMD tested on Windows hardware, their findings apply universally. The RAM requirements and model limitations are the same whether you're on Windows, Mac, or Linux. Here's what works, what RAM you need, and how to configure everything for your platform.
If you've been wondering whether your machine can handle local models, here's the definitive answer.
Understanding your hardware
First, let's check what you're working with. LM Studio makes this remarkably simple with visual indicators showing which models your hardware can handle.
Checking your RAM:
- Mac: Apple Menu → About This Mac → Memory
- Windows: Task Manager → Performance → Memory
- Linux:
free -hin terminal
The distinction between RAM and VRAM matters. System RAM determines which models you can load, while VRAM (on dedicated graphics cards) affects inference speed. For AMD systems with integrated graphics, you'll configure Variable Graphics Memory (VGM) to allocate system RAM for GPU tasks.
GGUF vs MLX: choosing your format
The only platform-specific choice is your model format:
GGUF (GPT-Generated Unified Format)
- Works on Windows, Linux, and Mac
- Extensive quantization options (2-bit through 16-bit)
- Broader compatibility across tools
- Choose this for Windows/Linux or cross-platform needs
MLX (Apple's Machine Learning Framework)
- Mac-only, optimized for Apple Silicon
- Leverages Metal and AMX acceleration
- Faster inference on M1/M2/M3 chips
- Choose this if you're exclusively on Mac
Quantization: balancing quality and performance
Quantization reduces model precision to save memory. To understand what you're trading off, consider that cloud APIs like Claude Sonnet 4.5 or GPT-5 run at full precision (16-bit or even 32-bit floating point) on massive server infrastructure. When you run locally, quantization makes these models fit on consumer hardware.
What the numbers mean:
- 4-bit: Reduces model size by ~75%. Like a compressed JPEG; you lose some detail but it's completely usable. Most users won't notice the quality difference for coding tasks.
- 8-bit: Reduces model size by ~50%. Better quality than 4-bit. More nuanced responses, fewer edge-case errors. A higher-quality JPEG with less compression.
- 16-bit: Full precision, matching cloud APIs. Requires 4x the memory of 4-bit but delivers maximum quality. The uncompressed original.
AMD's testing confirms 4-bit quantization delivers production-ready quality for coding tasks. The difference between 4-bit local and full-precision cloud is often less noticeable than the difference between model architectures themselves. A 4-bit Qwen3 Coder will outperform many full-precision smaller models.
Mac 36GB RAM x qwen/qwen3-coder-30b (4-bit)
Memory requirements example:
- Qwen3 Coder 30B at 4-bit: ~17GB download
- Qwen3 Coder 30B at 8-bit: ~32GB download
- Qwen3 Coder 30B at 16-bit: ~60GB download
With your hardware checked and quantization understood, here's exactly what you can run.
Model guide by RAM tier
Quick reference:
| RAM | Best Model | Download | Context | Compact Prompts | What You Get |
|---|---|---|---|---|---|
| 32GB | Qwen3 Coder 30B (4-bit) | 17GB | 32K | ON | Entry-level local coding |
| 64GB | Qwen3 Coder 30B (8-bit) | 32GB | 128K | OFF | Full Cline features |
| 128GB+ | GLM-4.5-Air (4-bit) | 60GB | 128K+ | OFF | Cloud-level performance |
32GB RAM: The minimum viable tier
Primary model: Qwen3 Coder 30B A3B (4-bit) – Despite 30B parameters, only 3.3B are active during inference. Choose GGUF for Windows/Linux, MLX for Mac.
Honorable mention: mistralai/magistral-small-2509, mistralai/devstral-small-2507
AMD's testing confirms this as the entry point. You'll need Compact Prompts enabled, which reduces some Cline features but maintains core coding capabilities. Many users successfully push beyond AMD's recommended 32K context all the way to 256k context.
64GB RAM: The sweet spot
Primary model: Qwen3 Coder 30B A3B (8-bit) – Same model, better quality
This unlocks the full Cline experience. Compact Prompts turn off, and model responses become noticeably more nuanced.
128GB+ RAM: The promised land
Primary model: GLM-4.5-Air (4-bit) – AMD's top pick with 106B parameters (12B active via MoE)
Honorable mention: Nousresearch/hermes-70B, openAI/gpt-0ss-120b
State-of-the-art local performance. You can run multiple models simultaneously and achieve genuinely cloud-competitive results.
Setting up your local stack
Once you've picked your model based on your RAM, the setup is straightforward.
LM Studio configuration
- Download the right model: Use LM Studio's search to find your chosen model. The interface shows compatibility with green checkmarks.
- Critical settings:
- Context Length: Match to your RAM tier
- Flash Attention: Essential for AMD hardware and high context
- KV Cache Quantization: Leave disabled for consistent performance
- Server setup:
- Navigate to Developer tab
- Load your model
- Start the server (default: http://127.0.0.1:1234)
Cline configuration
- Provider: Select LM Studio
- Model: Match your loaded model (e.g., qwen/qwen3-coder-30b)
- Context Window: Match LM Studio's setting
- Compact Prompts: Based on your RAM tier
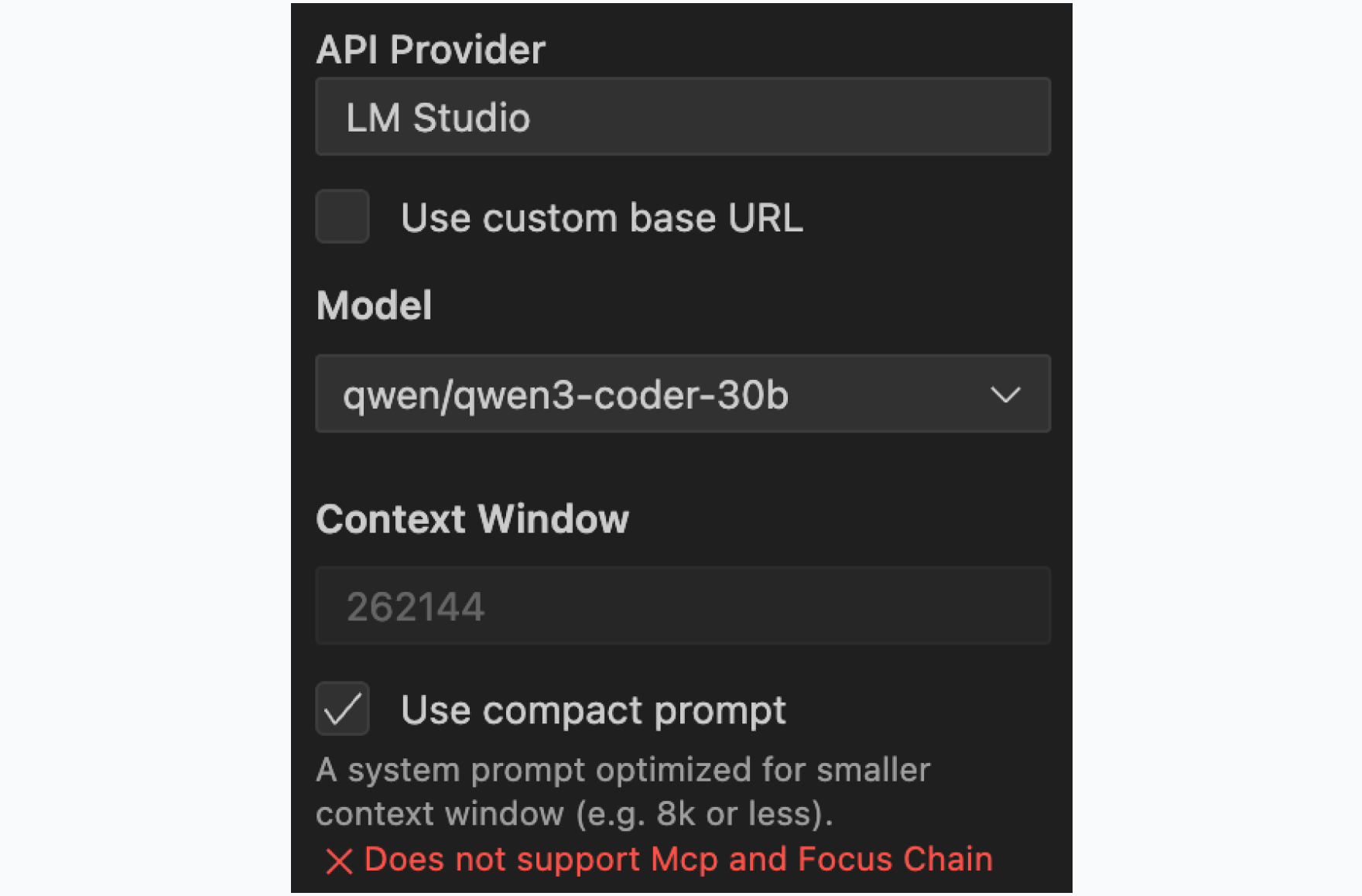
The compact prompt setting reduces the system prompt by 90% and is crucial for performance. By reducing Cline's prompt to ~10% of the original size, you dramatically improve responsiveness. The prompt weight that would normally slow down every interaction is lifted, making the model feel snappier and more responsive. You trade some advanced features (MCP tools, Focus Chain) for this performance boost, but core coding capabilities remain fully intact.
Platform-specific configuration
Windows users (AMD hardware)
AMD Ryzen AI platforms:
- Configure Variable Graphics Memory (VGM) through AMD Software: Adrenalin Edition
- Right-click desktop → AMD Software → Performance → Tuning
- Set dedicated graphics memory based on AMD's matrix
AMD Radeon graphics cards:
- Install AMD Software: Adrenalin Edition 25.8.1+ for llama.cpp support
- Radeon PRO users need PRO Edition 25.Q3 or higher
- No VGM configuration needed for dedicated cards
NVIDIA users:
- Ensure CUDA drivers are installed for GPU acceleration
- Use GGUF format for best compatibility
Mac users
- Use MLX format for Apple Silicon optimization (M1/M2/M3)
- No additional drivers needed
- Metal acceleration works out of the box
- For Intel Macs, use GGUF format
Linux users
- Use GGUF format
- Install CUDA (NVIDIA) or ROCm (AMD) drivers for GPU acceleration
- CPU-only inference works without additional setup
The models that didn't work
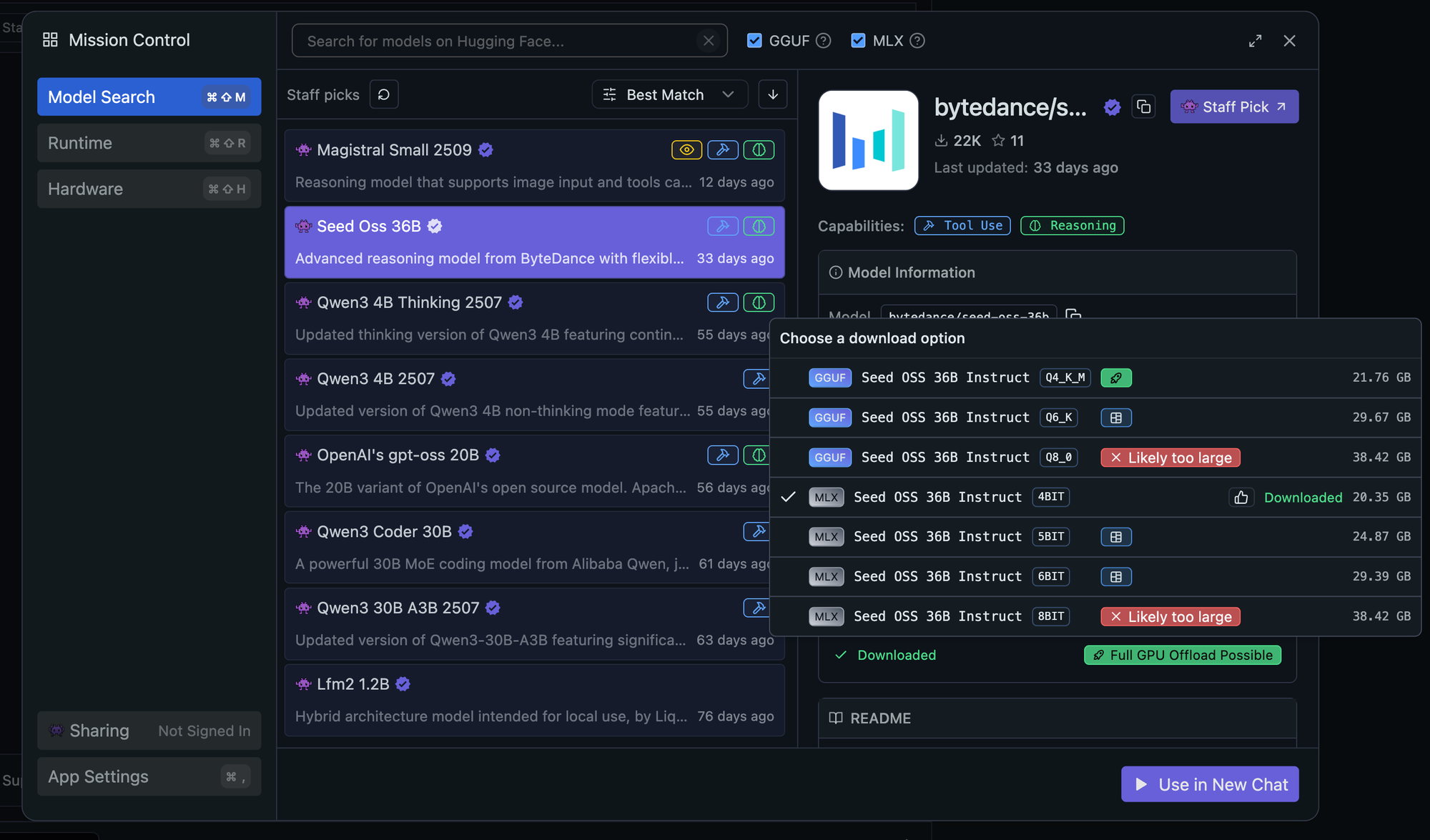
AMD's testing revealed that models smaller than Qwen3 Coder 30B consistently fail with Cline, producing broken outputs or refusing to execute commands properly. This includes popular smaller models that work well for chat but lack the capability for autonomous coding tasks. In our testing, these include gpt-oss-20b, bytedance/seed-oss-36b, and deepseek/deepseek-r1-0528-qwen3-8b.
This isn't a limitation of the models themselves but rather a mismatch between model capabilities and Cline's requirements for tool use, code understanding, and autonomous operation.
Getting started
Download LM Studio from https://lmstudio.ai and install Cline for VS Code. Search for your model based on your RAM tier, configure the settings we covered, and point Cline to your local endpoint.
Your hardware determines your options, but even entry-level 32GB machines can run genuinely useful local coding agents.
Ready to go local? Download Cline and join the discussion on r/Cline. Share your setup and results with the community on Discord.


