
Instant Code Generation is Here: Cline x Cerebras
Every developer knows the feeling. You're in flow, building something complex, and then – you wait. The model thinks. You watch the tokens slowly stream in. Your mind wanders. By the time the response arrives, you've lost your train of thought.
Today, that changes. We're partnering with Cerebras to deliver code generation at 2,000 tokens per second in Cline. That's 40x faster than typical providers.
No more waiting. Your thoughts flow directly into working code.
How They Do It
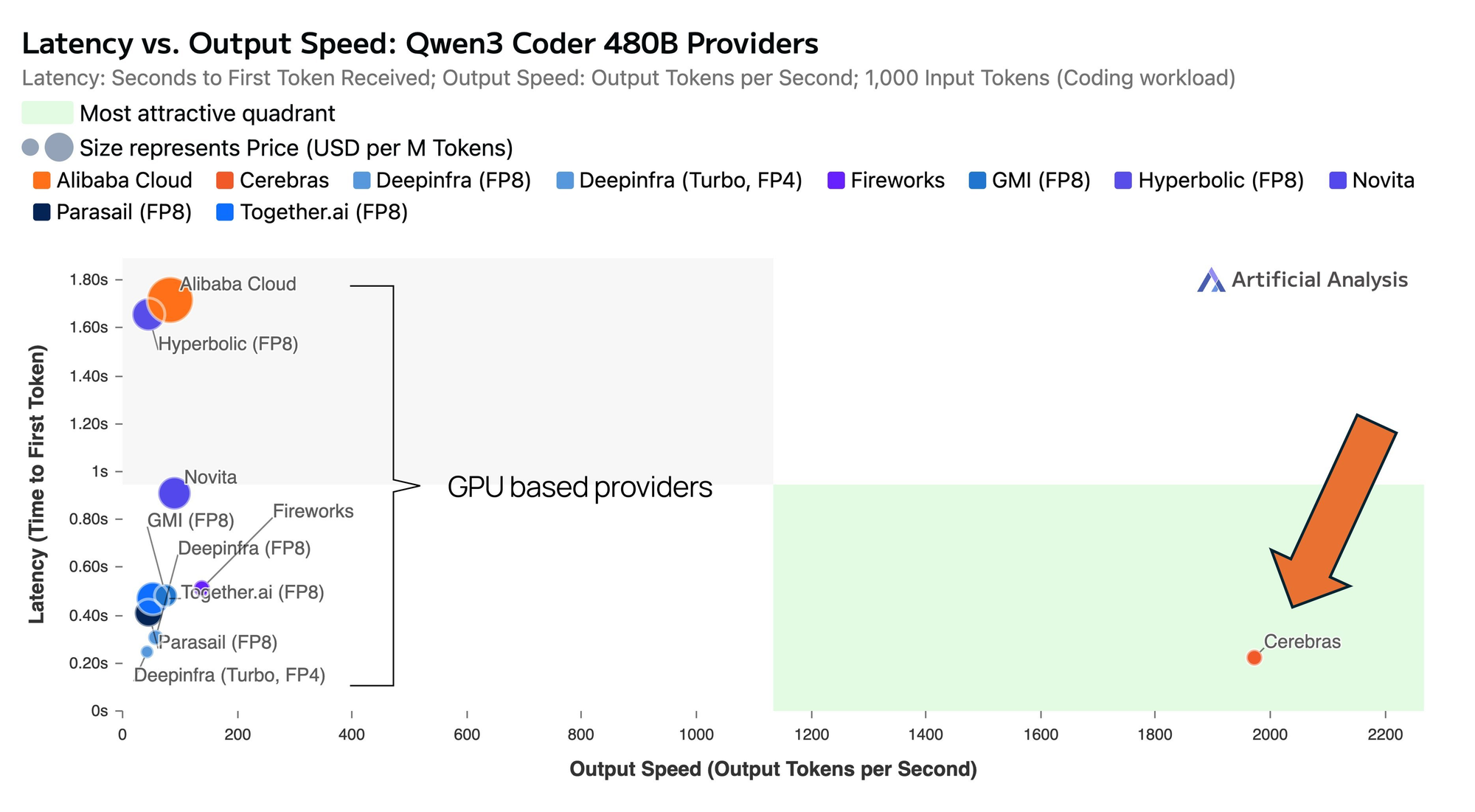
Cerebras didn't optimize existing hardware -- they built different hardware. Their Wafer-Scale Engine (WSE-3) is an entire silicon wafer functioning as a single chip. 900,000 AI cores. 44GB of on-chip SRAM. All model weights live on-chip, eliminating memory bottlenecks entirely.
The result: Raw performance that puts them alone in the "attractive quadrant" – minimal latency, maximum throughput.

This Cerebras integration exemplifies our approach. We're model and provider-agnostic by design, constantly evaluating and integrating breakthrough technologies. When something delivers real value to developers, we move fast to make it available to you.
Today it's Cerebras at 2,000 tokens/second. Tomorrow it might be something even faster. With Cline, you're always at the cutting edge without changing your workflow.
The Open-Source Wave
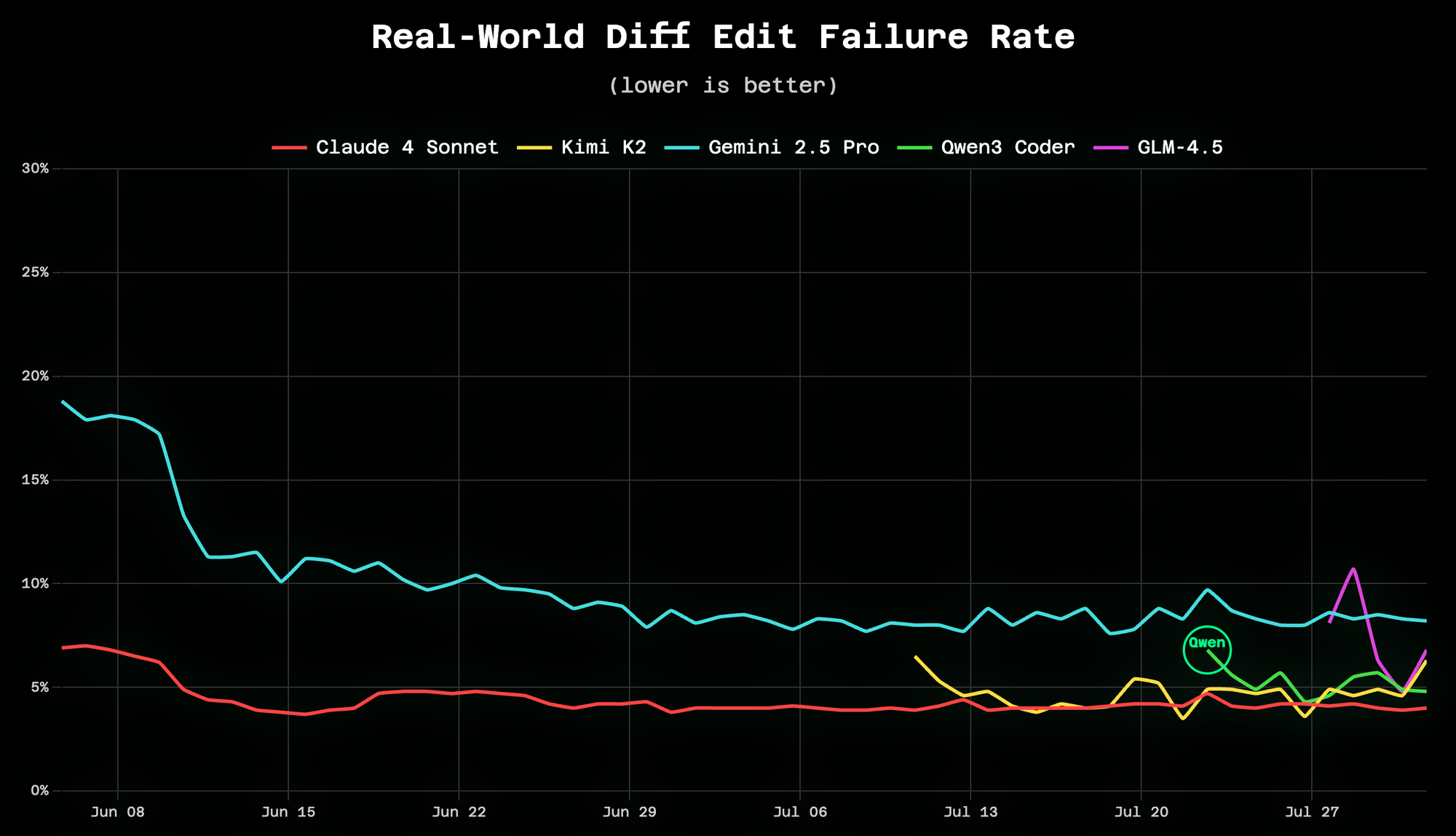
Fast inference with mediocre models is pointless. That's why we're excited about Qwen3 Coder – it's competitive with Claude Sonnet and beats GPT-4.1 on SWE-bench while running at 2,000 tokens/second on Cerebras.
This isn't a compromise. It's a frontier-quality coding model that happens to be open weight.
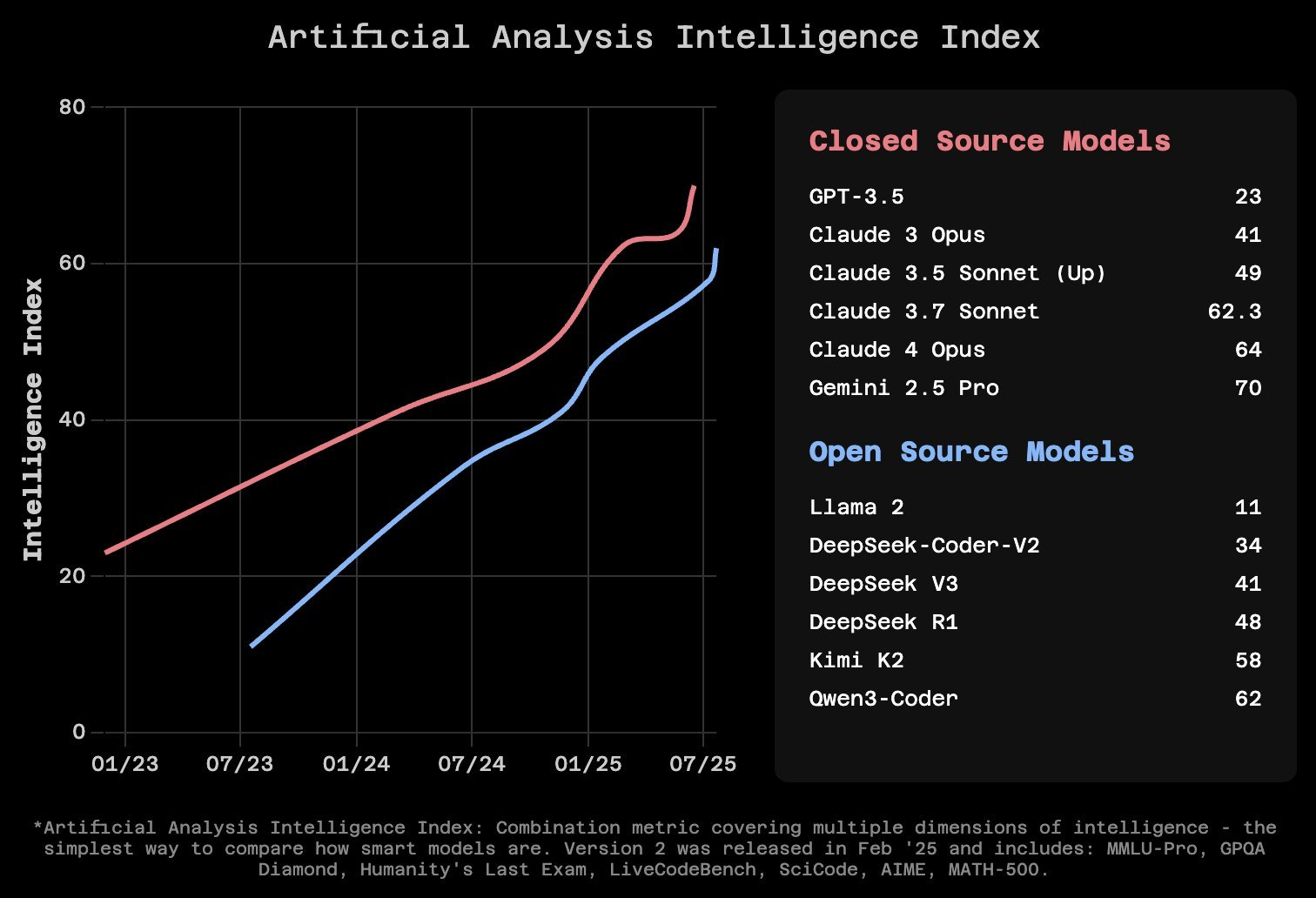
Qwen3 is part of a larger trend. Open-source models are rapidly converging with closed-source quality. Kimi K2 and GLM-4.5 are delivering 90% of the performance at 10% the cost.
When you pair these elite open models with specialized inference like Cerebras, you get performance that exceeds closed models on generic infrastructure. This is the future we're building toward.
Get Started in 30 Seconds
- Get your Cerebras API key: https://www.cerebras.ai/blog/introducing-cerebras-code
- Choose your tier:
- Free: 64K context, rate limited
- Pro ($50/mo): 131K context, 1K messages/day
- Max ($200/mo): 131K context, 5K messages/day
- Select Cerebras in Cline's provider dropdown & select qwen-3-coder-480b (use the free version if you're not on a paid plan).
