
DeepSeek's Wild Week: A View from the Developer Trenches
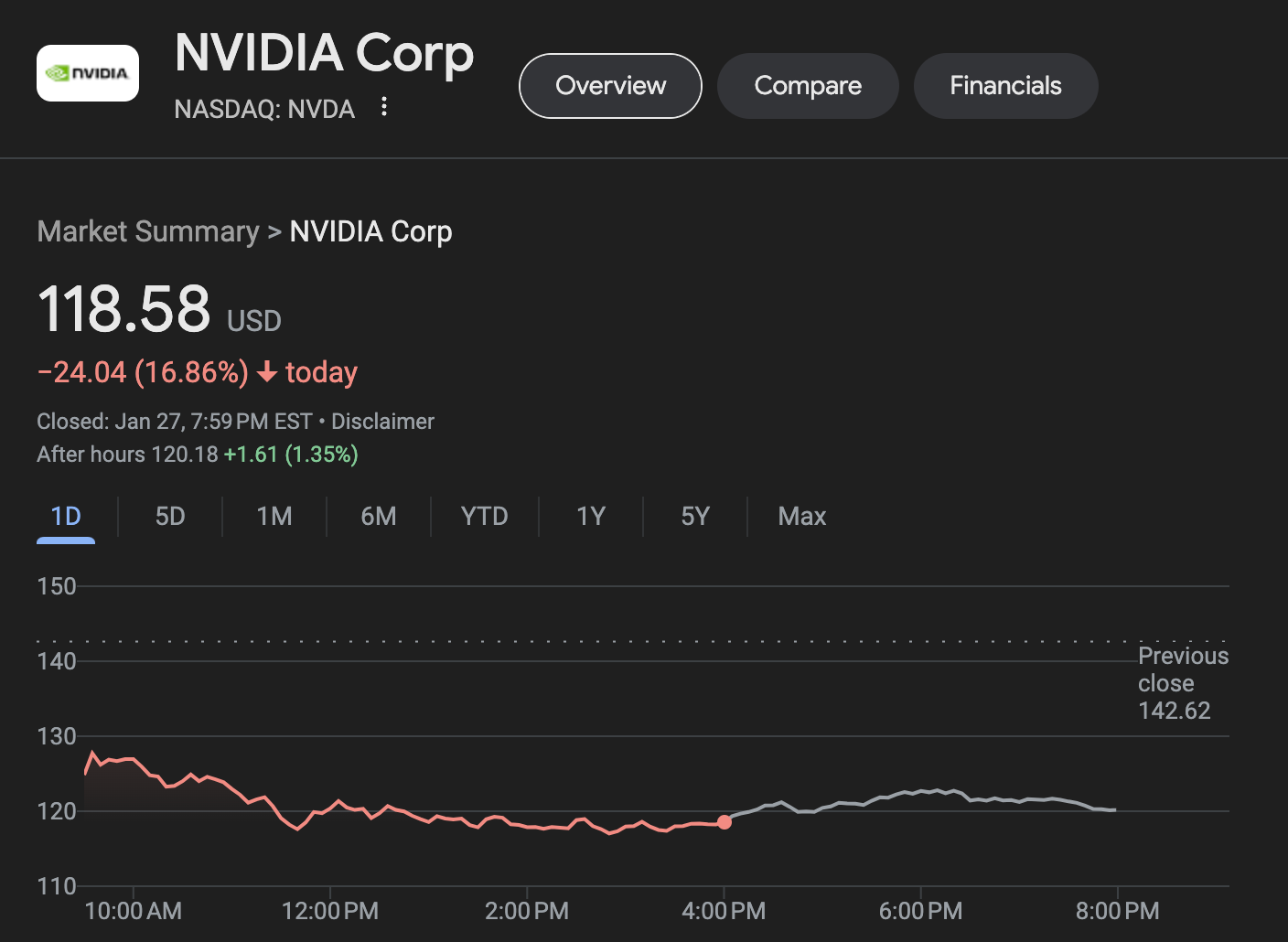
Last week, Chinese AI startup, DeepSeek, caused the biggest single-day drop in NVIDIA's history, wiping nearly $600 billion from the chip giant's market value. But while Wall Street panicked about DeepSeek's cost claims, Cline users in our community were discovering a more nuanced reality.
The Promise vs The Reality
"R1 is so hesitant to open and read files while Claude just bulldozes through them," observed one of our users. This perfectly captures the gap between DeepSeek's impressive benchmarks and the day-to-day developer experience.
While the benchmarks show DeepSeek matching or beating industry leaders, our community has found that each model has its sweet spot:
"I use R1 to plan things and V3 to execute, give it a try it will blow your mind"
"It's like you use R1 for architect mode and Sonnet for Editor"
"I like R1, I feel like it over thinks a little too much and does stuff you don't ask it to"
The Infrastructure Reality
DeepSeek's rapid rise to #1 in the App Store has come with serious growing pains. Our community has been tracking the issues in real-time:
"Their API is running REALLY slowly. With my simple XHR Request test, it took 30 seconds to respond to me," reported one developer. Another noted, "unfortunately deepseek is still unusable to me, super slow through their api, over 2 min wait times if not more."
The problems aren't limited to speed. Recent reports indicate:
- API degradation and timeouts
- Web chat outages
- Registration restrictions to Chinese phone numbers
- Service disruptions from "large-scale malicious attacks"
The Cost Factor
Despite the infrastructure challenges, DeepSeek's pricing remains compelling. One user reports:
"I haven't burnt $10 yet and I've put around 12 Million tokens through that setup"
The official pricing shows:
- DeepSeek: $0.55/million input tokens, $2.19/million output tokens
- OpenAI's model: $15/million input tokens, $60/million output tokens
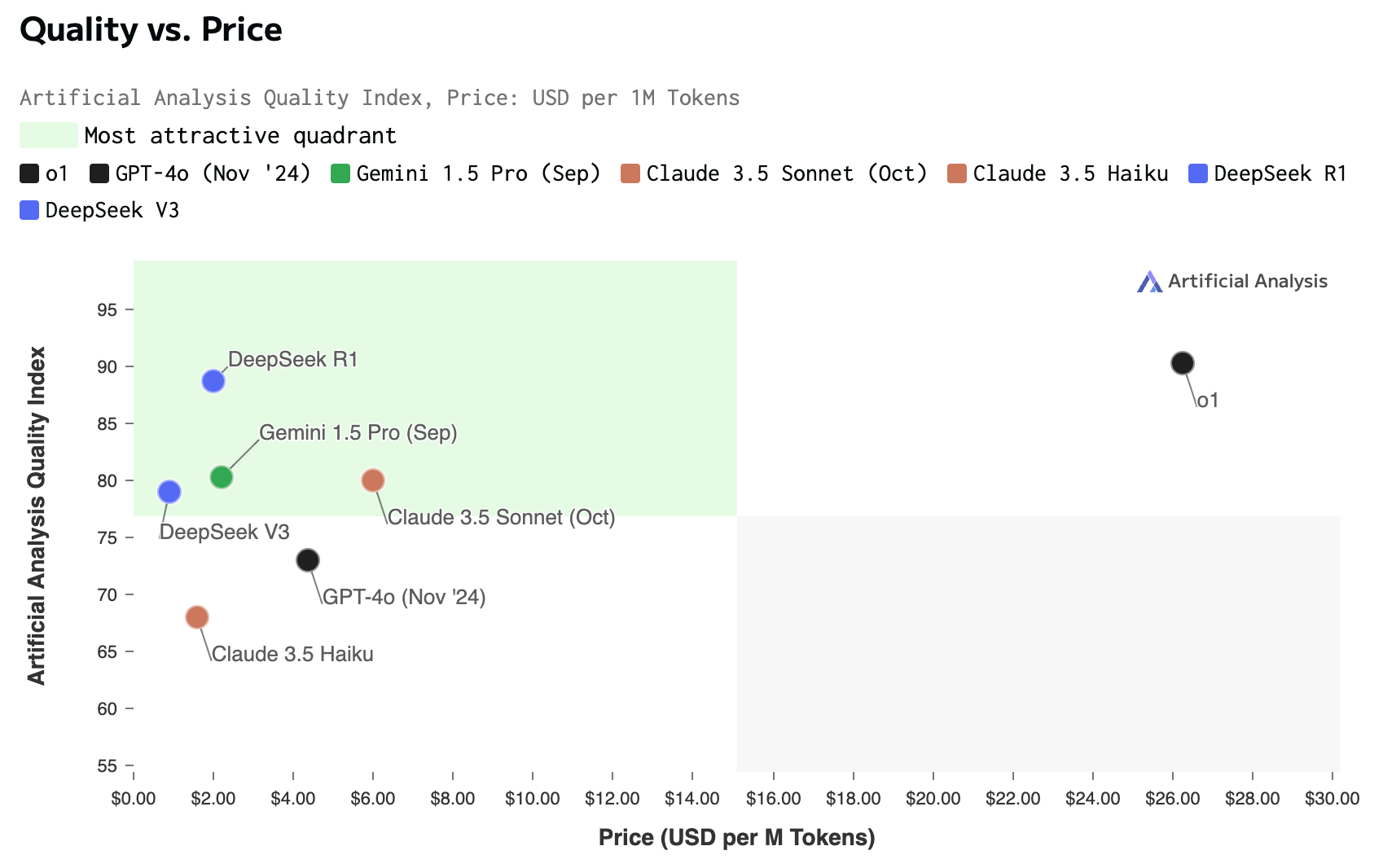
Real-World Usage Patterns
Our community has developed some interesting workflows to maximize DeepSeek's strengths while working around its limitations:
- Model Combinations
- Using R1 for planning and 3.5-Sonnet for implementation
- Switching to DeepSeek V3 for cost-sensitive projects
- Maintaining Claude as a reliable fallback
- API Alternatives
"I just switched to DeepSeek directly and it's like 10x faster it seems for R1. OpenRouter has been slow for me lately"
- Local Deployments
Running local instances comes with its own challenges: "Even with all this the 70b model is gonna be super slow, maybe 1-2 tokens/sec, and the system is pretty unresponsive while its going."
Looking Forward
The immediate future of DeepSeek remains uncertain. As one community member put it:
"I think it will be better when whatever is happening now passes; even deepseek-chat worked great for me the other day. And with the cost difference, it is a no-brainer. It needs to work more reliably, but the model is impressive."
The Bottom Line
DeepSeek's emergence represents both the promise and perils of democratizing AI development. While their cost efficiency claims sent shockwaves through the market, the real story is playing out in developer communities like ours, where the practical challenges of using these models are being discovered and solved in real-time.
For now, our community's consensus seems to be: DeepSeek is promising but not yet ready for mission-critical applications. As one developer put it:
"The price difference is significant enough that it's worth dealing with some inconvenience - but not for anything mission-critical yet."
This article is based on real experiences from our developer community. Join our Discord and r/cline to share your own experiences and stay updated on the latest developments.


