
3 Seductive Traps in Agent Building
In building AI agents at Cline, we've discovered that the most dangerous ideas aren't the obviously bad ones, they're the seductive ones that sound brilliant in theory but fail in practice. These "mind viruses" have infected the entire industry, costing millions in wasted engineering hours and leading teams down architectural dead ends.
Here are the three most pervasive traps we see teams fall into:
- Multi-Agent Orchestration
- RAG (Retrieval Augmented Generation) via indexed codebases
- More Instructions = Better Results
Let's explore why!
(1) Multi-Agent Orchestration
The sci-fi vision of agents (‘rear agent, quarter agent, analyzer agent, orchestrator agent’) sending out a swarm of sub-agents and combining their results sounds compelling, but in reality, most useful agentic work is single-threaded.
The strongest progress in multi-agent systems so far has come from Anthropic, yet even they acknowledge that building and aligning multiple agents is extremely difficult. As their team puts it:
"The compound nature of errors in agentic systems means that minor issues for traditional software can derail agents entirely. One step failing can cause agents to explore entirely different trajectories, leading to unpredictable outcomes. For all the reasons described in this post, the gap between prototype and production is often wider than anticipated."
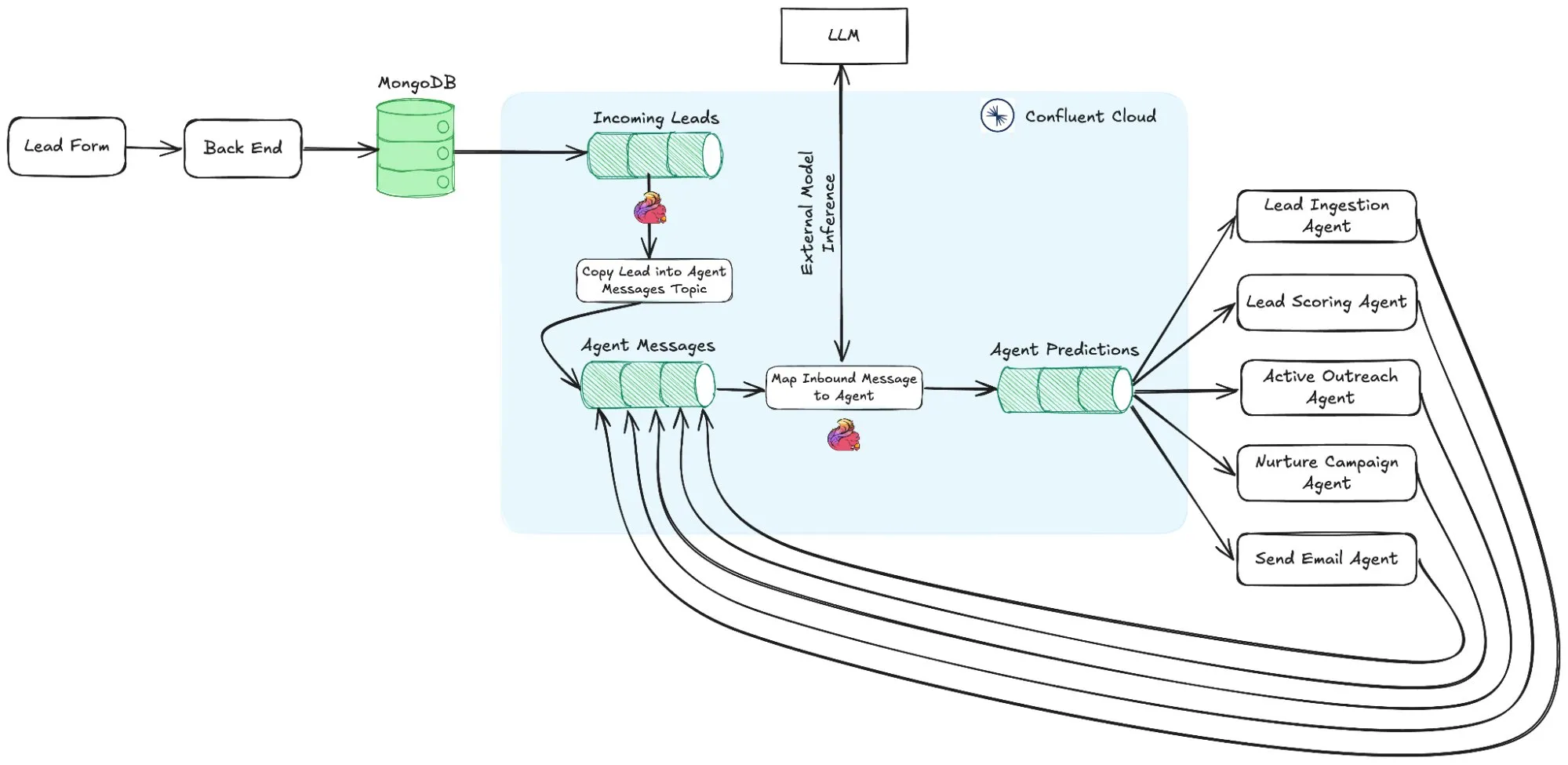
This is not to say that we are completely opposed to multi agents, for small specific use cases its totally plausible to have subagents with limited tool capabilities.
Take, for example, a case where a main agent thread spawns several subagents to read files in parallel. Alternatively, you might use subagents for trivial tasks like fetching from the web. But most of this is essentially the same as making a parallel tool call, so I’m not even sure it qualifies as “true” multi-agent orchestration.
(2) RAG (Retrieval Augmented Generation)
RAG is another seductive trap carried over from the era of smaller context windows, where giving your agent the ability to query “the entire codebase” felt enticing. But the RAG hype doesn’t translate into practical coding agent workflows, since it often produces scattered code without providing the model any real “contextual understanding.” It looks powerful on paper, yet in practice even something as simple as GREP can work better, especially for agents.
It’s almost always better for the agent to list files, search through them with grep, and then open and read the whole thing, just like a person would. Cline set the standard with this approach from the start, and it has since defined the meta, with both Amp Code and Cursor following suit.
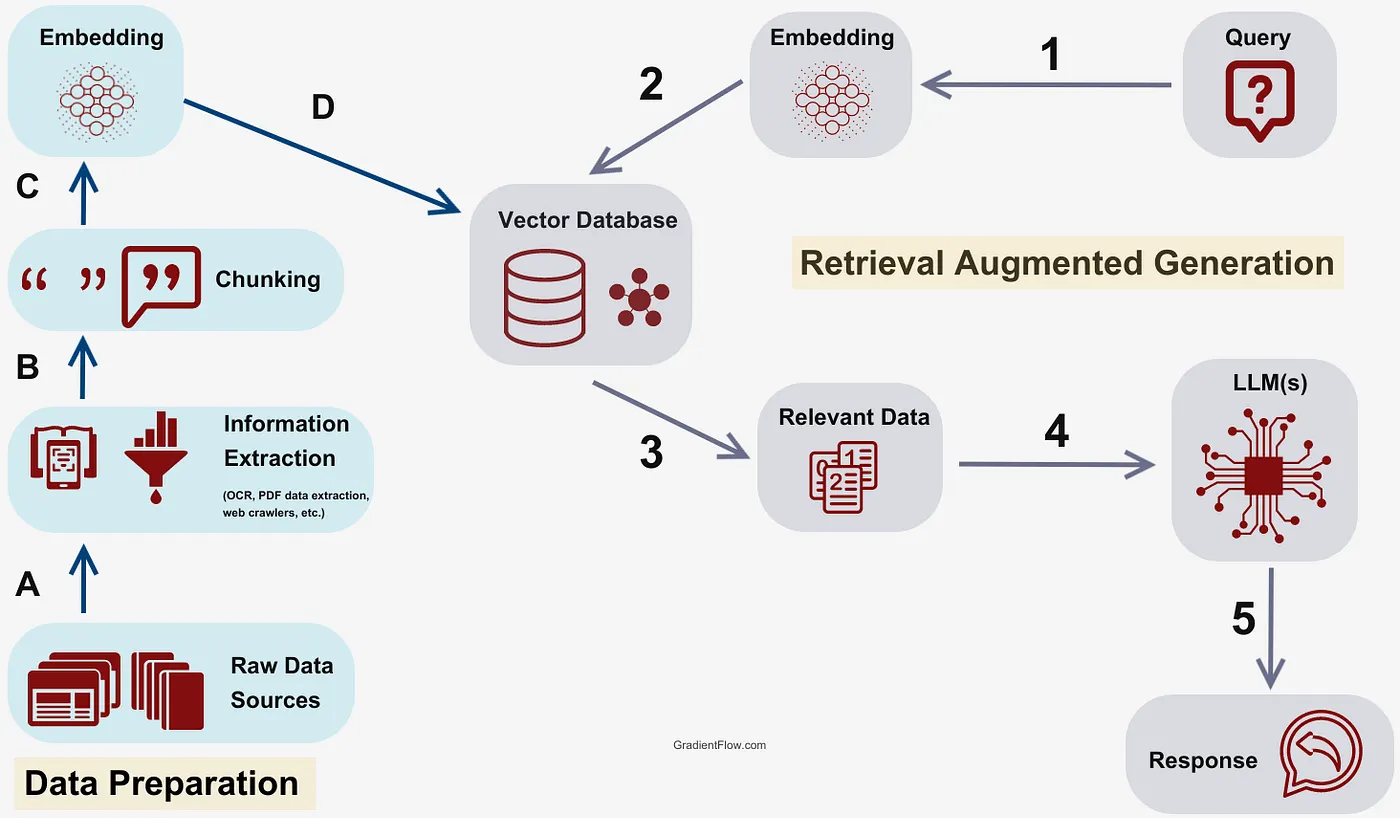
Most companies began with vector databases because when “chat with code” VS Code extensions first appeared in 2023, models only had an 8,092 token context windows, so every line squeezed into the model had to be carefully crafted. At the time this made a lot of sense, which is why so much infrastructure and hype went into vector database companies, with some raising hundreds of millions, like Pinecone. Cline launched in July 2024, when the leading coding model was Claude 3.5 Sonnet with a 200K token context window, so it was never constrained by the need to stitch together unrelated context snippets.
(3) More Instructions = Better Results
The myth that stacking the system prompt with more and more “instructions” makes models smarter is flat out wrong. Overloading the prompt only confuses the model, since extra instructions often conflict and create noise. You end up playing whack-a-mole with behaviors instead of getting useful output. For most frontier models today, it is better to step back and let them work, not keep yelling at them through the prompt. Measure your words carefully.
When Cline launched in mid-2024, Sonnet 3.5 was the leading model, and at the time it made sense to pack prompts with examples and ideas. But when the Sonnet 4 family arrived, that approach broke completely, and every other agentic system broke with it. Through iteration we realized the core issue: too much instruction creates contradictions, and contradictions create confusion.
The new frontier models, Claude 4, Gemini 2.5, and GPT-5, are much better at following terse directions. They do not need essays, they need the bare minimum. That is the new reality.
Multi-agent orchestration, RAG, and overstuffed prompts looked compelling on paper, but none survived contact with real development workflows. The agents that win are the ones that embrace simplicity: read code like a developer, trust the model's capabilities, and get out of the way.
While the industry continues chasing architectural complexity, the fundamentals have already shifted. Less is more, clarity beats cleverness, and the best AI agent is often the simplest one.
-Ara