
Why Patterns Matter: Lessons From Hyper-Growth Startups
I've heard it said that "patterns are what companies talk about when they're dying". This may be true, but it is also what companies talk about once they've hit PMF.
Don't fool yourself, do you really need scale?
If you haven't experienced a hyper growth startup before, it can be easy to dismiss things like composability, scalability, security, testability, redundancy, CI/CD, and the like as a needless waste of time. It's true that most startups think about these things way too early. Until you reach PMF, all of these things are a pure waste of time and distract your precious resources from the problems that truly matter. It is also true that most startups that have reached PMF start thinking about these things way too late. They handle these things in a reactive manner, and in the process, stunt their own growth potential.
Lessons from the trenches of hyper growth
I've been lucky enough in my life to be party to two extremely fast growing startups: Snowball and Cline. At Snowball, we followed the pattern of most startups – we only began addressing scaling, performance, and efficiency issues when it was painfully obvious that it was slowing us down. One of our early signs of PMF was when our community built and hosted their own web app for accessing our smart contracts (something I failed to do upon launch due to a family emergency). This level of community involvement and dedication is a huge harbinger of success, but, unfortunately, the community did not build the app for composability and scale. Very quickly, the spaghetti-code mess began to prevent us from shipping as fast as our competitors. Both myself and my co-founder were working 10-12 hours a day, 7 days a week, doing nothing but front-end feature development, and we were still falling behind and losing users to our competition! One day I decided enough was enough, and I refactored the web-app over the course of a week, ultimately increasing our feature throughput over 100x. Further improvements to our smart contract deployment system improved output by another ~50x. This immediately turned the company around and brought us from a total deathspiral of churn to a three month bonanza of new users and revenue growth (ultimately reaching $7.8M ARR 6 months post launch).
Even with all this success, our growth ultimately stalled again after a 2nd scalability hiccup. This time, due to a technical dependency. In late August, 2021, the Avalanche blockchain saw a monstrous uptick in user volume as a result of a popular social media post from a major Ethereum ecosystem influencer. Usership tripled literally overnight. Although our systems could handle the volume (barely), all of the dapps in the space shared the same weakness: the public RPC endpoint hosted by Avalanche. All at once, almost every project on Avalanche stopped responding, and the crush of high value users disappeared as quickly as they came. We at Snowball, just like everyone else in the space, immediately turned around to build our own RPC Nodes to prevent this kind of failure from ever happening again. Unfortunately, it was too late. The wave of Ethereum transplants receded as quickly as it came. Volumes for Snowball and the Avalanche ecosystem as a whole never recovered.
Ultimately due to us being reactive instead of proactive about scaling issues, what could have been a generational company became a flash in the pan.
Maximum Aerodynamic Pressure
Fast forward several years and Cline is seeing an even greater level of adoption. We're used by many of the top engineers at the most well reputed companies around the world. Many of the Snowball veterans are here with me and we've earned the certainty that as soon as numbers start going up and to the right, it's time to start thinking about scale – before it affects your bottom line. So the question becomes, how can you scale gracefully?
The answer now is the same as it has been: patterns. There is no reason to re-invent the wheel. The tried-and-true methods which have stood the test of time and the weight of billions of TPS are known, common, and there for the taking – if you're wise enough to reach for them. It takes experience to know exactly when it's time to employ any given technique, but some things are prerequisites for others, and you should never underestimate how time consuming and tedious some of these changes can prove to be. Once you have PMF, it's time to start implementing the basics – immediately!
Step 1: Prepare for Change
Your codebase must be designed for change. In order to implement any scalability patterns, you first must be able to change your system at all. This sounds easy, but it's actually quite unintuitive to design a system for change and can be challenging for the uninitiated. The ability for a codebase to change is called Modularity. For a codebase to be modular, it cannot be tightly coupled. Stated another way: systems should have minimal dependencies on each-other. This is achieved through several approaches, including the following.
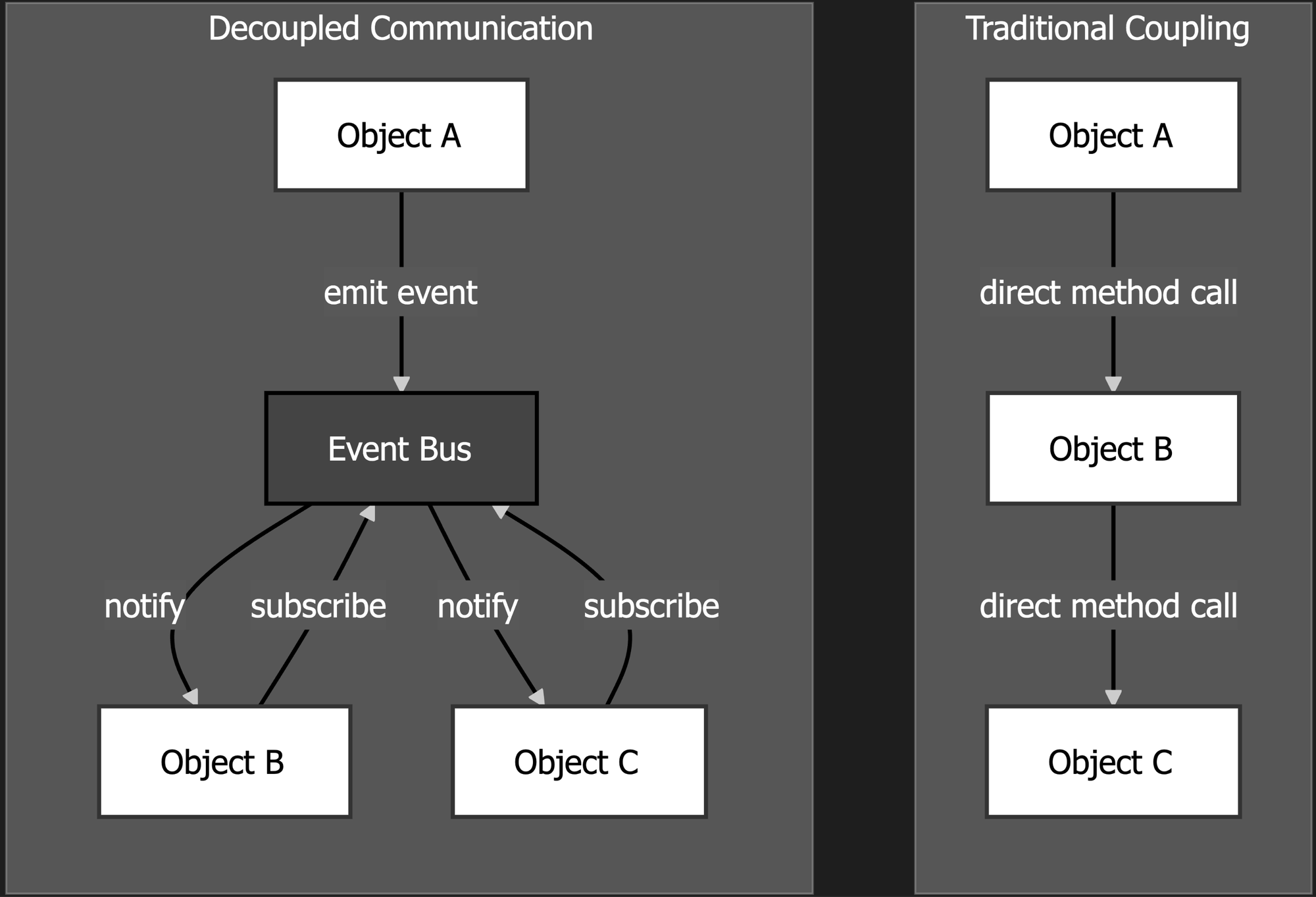
Decoupled Communication
Most simple applications have direct (and thereby tightly coupled) communication between a sender and a receiver. For example, in OOP object A might call a method in object B, making A dependent on B. In a decoupled communication system, you might use an Observer pattern, an Event Bus, or even a Pub/Sub system, depending on the scope of the communication. In such a system, object A would emit an event to which object B would have previously subscribed, and can respond to via a callback. In this system, both object A and object B would be dependent on the communication system, and may even have no awareness of each other at all.
Such a system allows you to quickly add new objects that might also respond to, or emit events without introducing complex dependency patterns or risking dependency cycles (which many languages strictly forbid).
Ports and Adapters
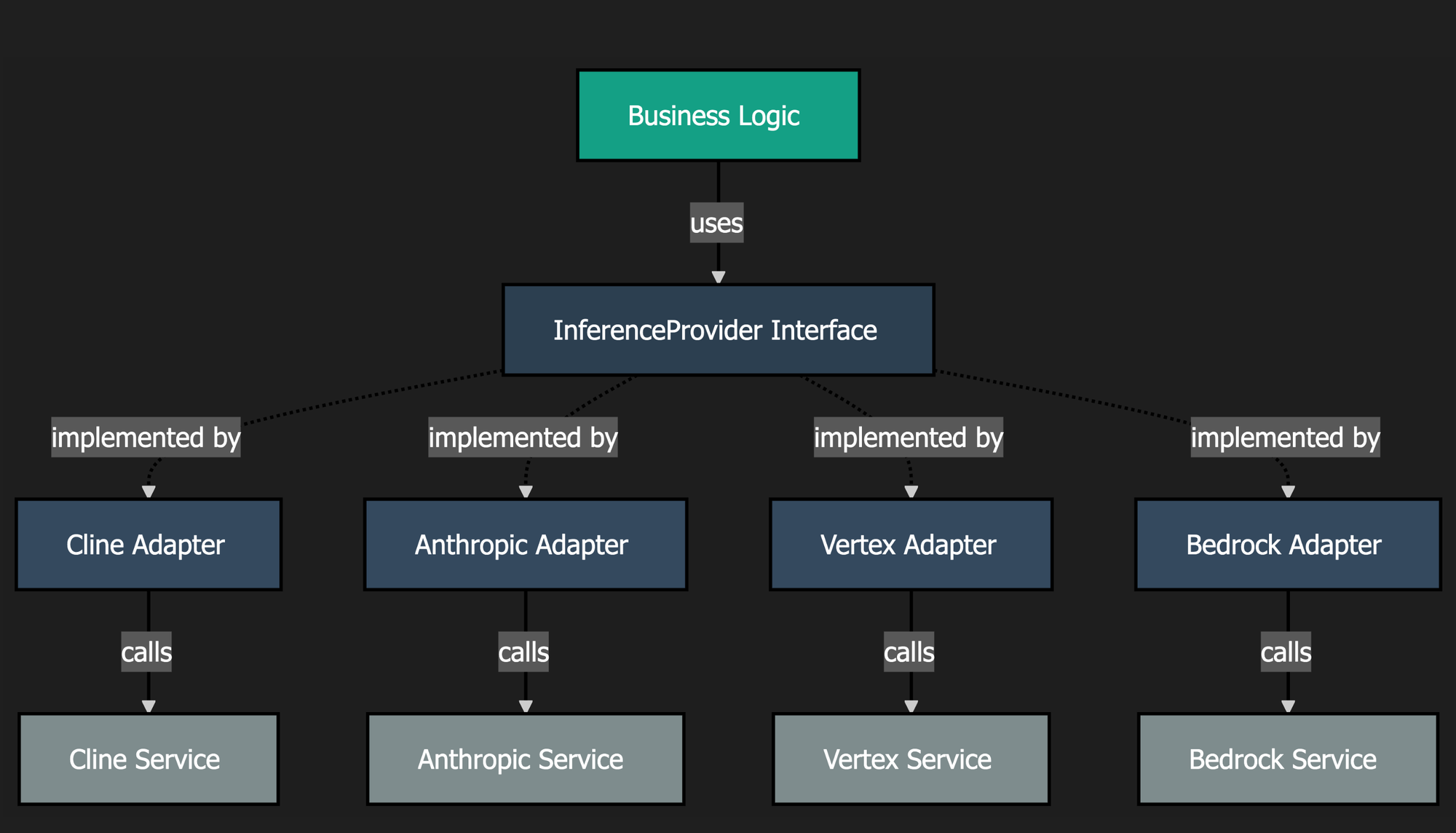
Many applications intermix logic specific to external dependencies with their own business logic. This brittle pattern makes it very challenging to adopt alternatives, introduce fallbacks, or switch to a competitive offering. At Cline, for example, we aim to decouple specific inference providers or models from the business logic of the system so that adding new providers and new models becomes a trivial task instead of a tedious and time consuming process, achievable by only the most senior engineers. The means of accomplishing this is via Ports and Adapters.
Ports are a specific implementation of the Interface pattern where multiple unique implementations (called Adapters) are able to adhere to the Interface. In the case of Cline, we can create a Port called InferenceProvider and numerous Adapters that satisfy that port including Cline, Anthropic, Vertex, and Bedrock. In all of our business logic, we would only reference the InferenceProvider port, such that business logic is only loosely coupled with these external dependencies, and we can centralize the code footprint necessary for adding a new provider. That is, instead of having to touch thousands of lines across dozens of files, we may only have to add hundreds of lines to a single file, namely the definition of the new Adapter.
Dependency Injection
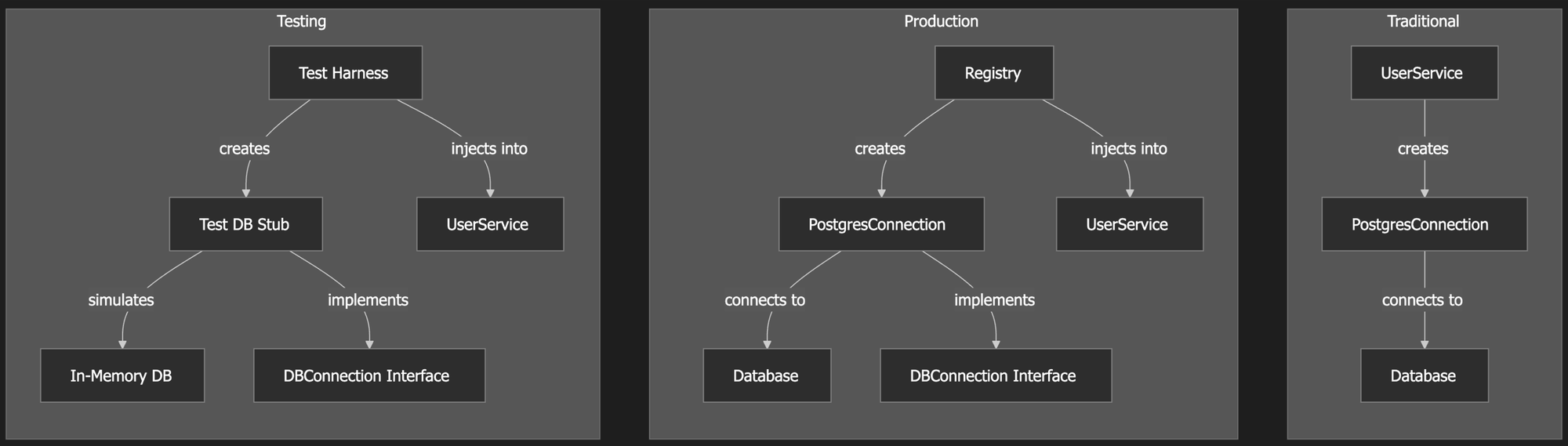
Many applications directly instantiate their dependencies at the point of use. Take for example, a UserService. This service might create its own database connection when constructed, embedding configuration details and directly binding itself to a specific implementation. UserService might include a line like: this.pg = new PostgresConnection(config). The issue with this approach is immediately apparent when writing automated tests. If UserService creates its own database connection, you can't test the service without a running database. Furthermore, if you later want to switch database providers or connection parameters, you'd need to modify every class that creates a database connection.
At Cline, we leverage dependency injection to invert this control flow. Rather than having components create their dependencies, these dependencies are provided (injected) from the outside. UserService might now declare: constructor(pg: PostgresConnection). You can go even further and combine this with Ports and Adapters with: constructor(db: DBConnection) and remain blissfully unaware of how that connection is configured or even what type of database it's actually connecting to. This approach centralizes configuration, allows for substantial changes to our database interactions without modifying business logic, and crucially, makes testing far simpler. Instead of requiring a real database for automated tests, we can inject stubs, fakes, or emulators that mimic database behavior without the overhead or complexity.
This pattern has enabled us to migrate portions of our database infrastructure, implement proper testing at scale, and roll out connection pooling optimizations all without touching the vast majority of our business logic. Components declare what they need without concerning themselves with how those needs are satisfied, making the entire system far more adaptable to change.
The Inflection Point: When Theory Meets Reality
When your startup begins to experience real growth, there's a critical inflection point where theoretical concerns about scalability transform into pressing, immediate problems. The patterns discussed here serve as foundational building blocks that enable your system to evolve without requiring complete rewrites.
These patterns aren't academic exercises or over-engineering, they're battle-tested approaches that become essential once you've found product-market fit. The key is timing: too early, and you're wasting precious resources solving problems you don't have; too late, and you're trying to replace the engine while the jet is already taking off.
The lesson is clear: build for what you have today, but design with tomorrow's scale in mind. When your company's growth curve begins to steepen, you'll already have the architectural foundation needed to support that growth rather than be crushed by it. In the world of high-growth startups, this preparedness often makes the difference between becoming a market leader and becoming just another cautionary tale.