
Improving Diff Edits by 10%
When it comes to modifying code, Cline has two primary methods in its toolkit:
1. write_to_file for creating or overwriting entire files, and
2. replace_in_file for making surgical, targeted changes (diff edits).
We call these targeted changes "diff edits," and their reliability is fundamental to the agent's performance. As part of our push to optimize every core subsystem of the agent, we've been intensely focused on improving the success rate of these diff edits.
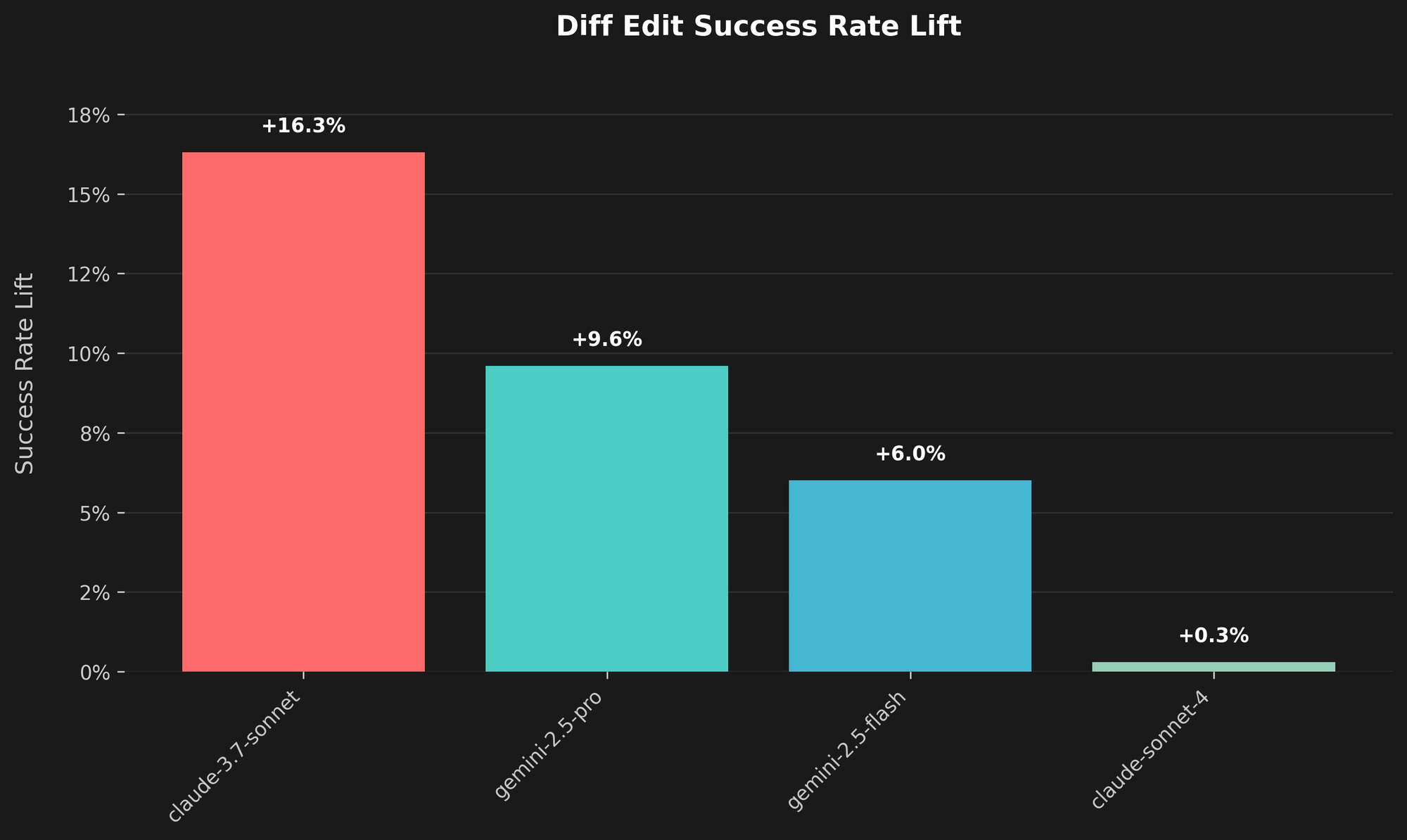
The result? We recently released a new diff-apply algorithm and model-specific prompt changes that have improved the diffEditSuccess rate by over 10% on average across all models.
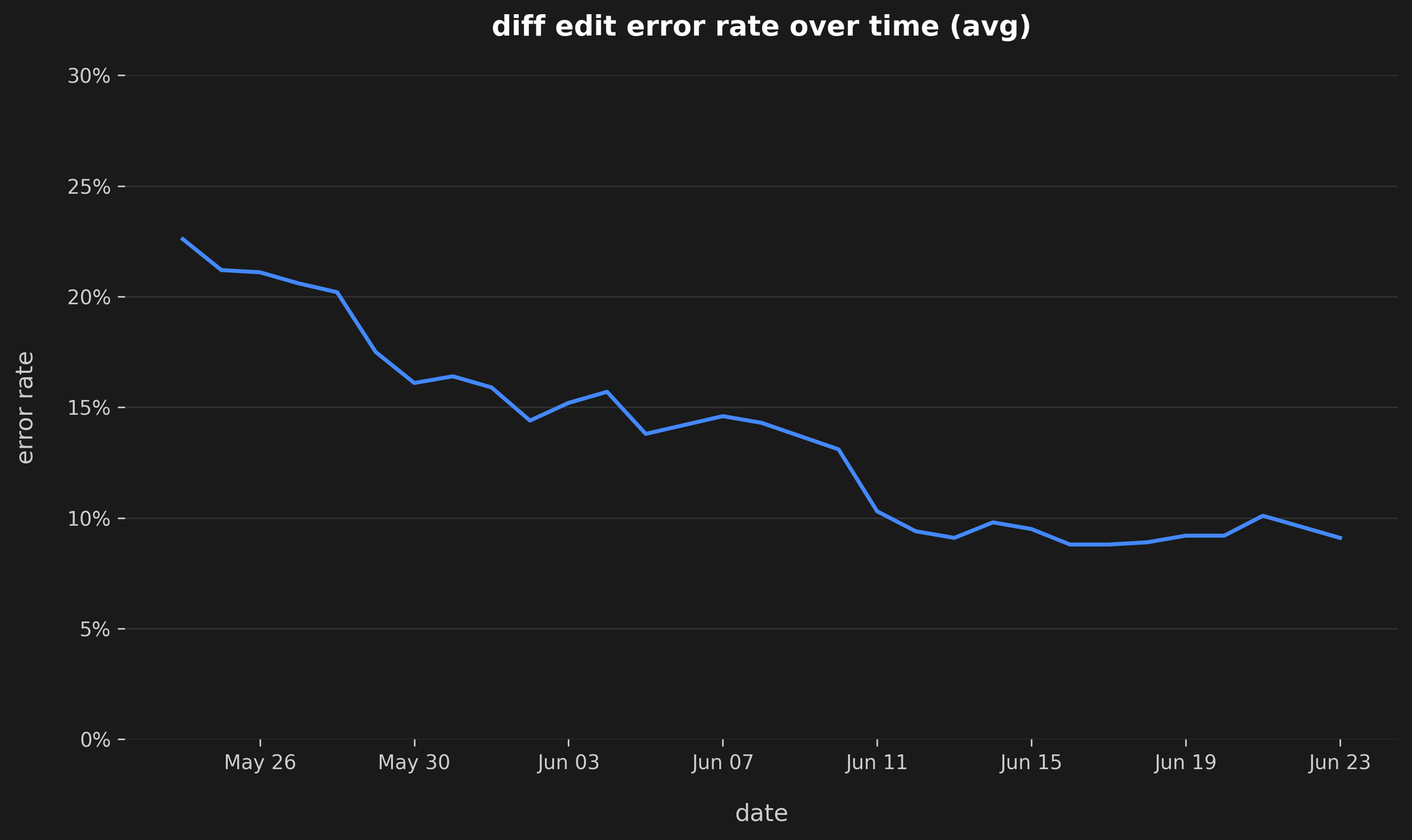
To achieve this, we built an open-source evaluation system to rigorously test every component of the diff-editing pipeline. This system allows us to systematically alter each component – including the system prompt, parsing logic, and the diff-apply algorithm itself – and test them against a suite of real-world user scenarios we've collected internally.
Our evaluation framework quickly uncovered a common and frustrating failure case: many LLMs, despite being explicitly prompted to produce diffs in the correct order, would often return them out of sequence. This is a fundamental problem of improper instruction-following.
Our solution was two-fold. First, we developed a new, "order-invariant multi-diff apply" algorithm. In simple terms, it can correctly apply the series of search-and-replace blocks even when the model provides them in the wrong order. Second, we added support for multiple diff formats to account for model-specific quirks. For example, Anthropic's models are optimized for - --/+++ markers, while Gemini and xAI models perform better with >>>/<<< blocks. Our system now handles both, ensuring higher reliability regardless of the user's chosen model. These changes together have had a significant impact on reliability.
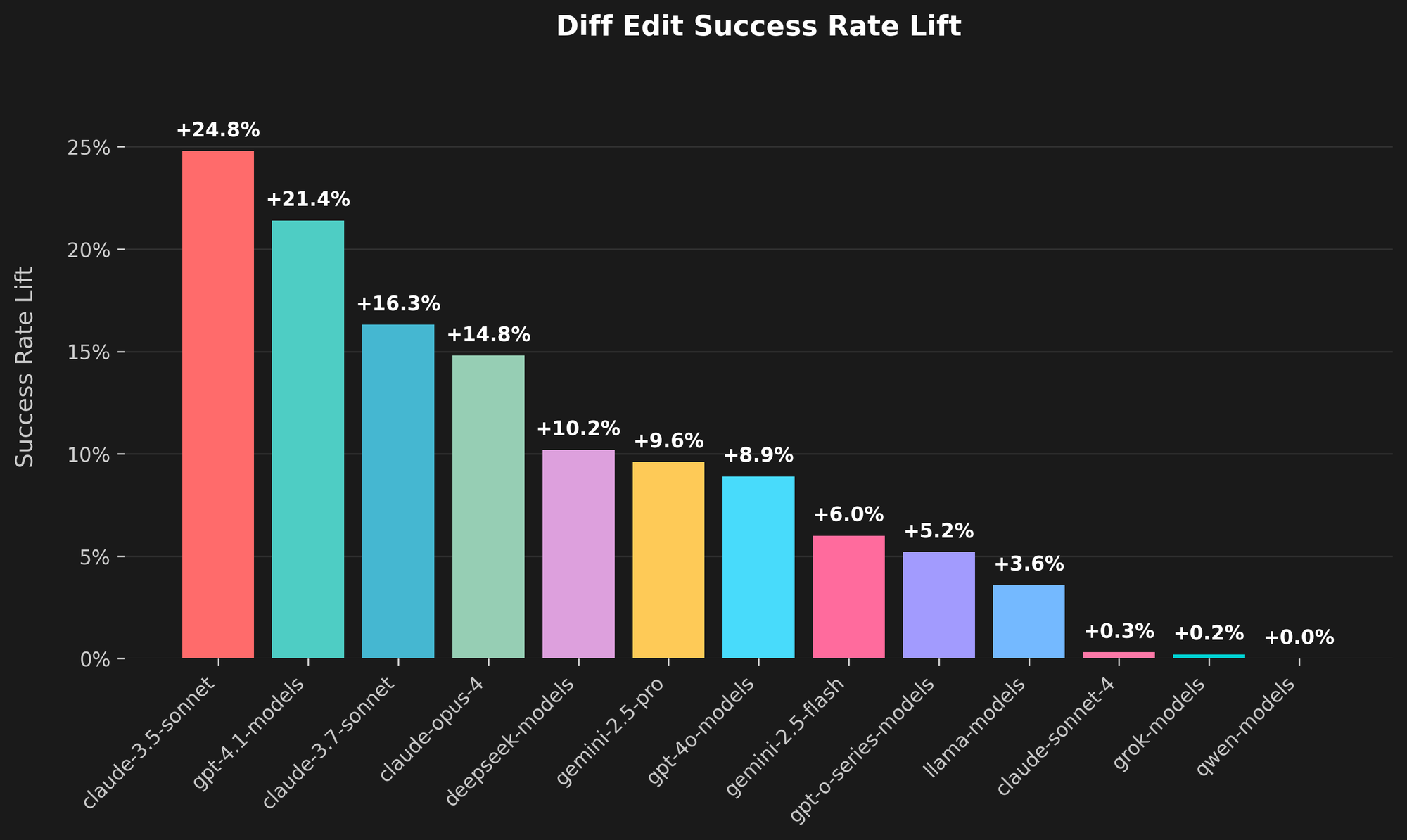
The data shows a clear lift across the board. For users connecting Cline to Claude 3.5 Sonnet, the success rate of diff edits has increased by nearly 25%. Other models show significant gains as well, with GPT-4.1 models improving by over 21% and Claude Opus 4 by almost 15%.
This is what building in the agentic paradigm looks like -- it's a continuous process of measurement, analysis, and targeted improvements. By building tools to evaluate our own systems, we can move beyond anecdotal evidence and make data-driven decisions that result in a more capable and reliable agent for everyone.
We're aiming for a 0% error rate, and this is a significant step in that direction.
If you're interested in the technical details or want to use our evaluation framework for your own projects, you can find the entire system open-sourced on our GitHub here.
Work like this is happening every day at Cline. If you're passionate about building the future of software development and want to solve these kinds of problems, check out our open roles here.